[CUDA] Reuse blocks with record_stream during CUDA Graph capture in the CUDACachingAllocator #158352
https://github.com/pytorch/pytorch/pull/158352
专栏另一篇文章解读了record_stream相关内容,但CUDACachingAllocator源码中存在一个分支,会根据CUDAAllocatorConfig::graph_capture_record_stream_reuse()判断是否free和malloc某个block,这里填个坑,找一下对应的pr看是怎么复用的。
背景:CUDA Graph 下显存管理限制
在 CUDA Graph 捕获过程中,CUDACachingAllocator对内存的管理存在一个关键限制:必须等到捕获结束后才能回收内存块。这一限制源于 CUDA 的底层约束 —— 捕获阶段不允许查询event状态(因为此时 CUDA 操作尚未执行),而CUDACachingAllocator依赖事件驱动逻辑判断内存块是否可回收。而这会导致本该被释放的block未能被正确释放,直到捕获完全结束,比如free中的代码片段:
if (!block->stream_uses.empty()) {
if (C10_UNLIKELY(!captures_underway.empty())) {
// It's forbidden to cudaEventQuery an event recorded during CUDA graph
// capture. We conservatively defer recording end-of-life events until
// the next call to process_events() (which won't happen until no
// captures are underway)
needs_events_deferred_until_no_capture.push_back(block);
cudaGraph下安全的多流复用
为实现安全重用,PR 首先明确了两个核心术语,作为后续判断逻辑的基础:
- Free marker:通过cudaGraphAddEmptyNode创建的 “捕获合法” 空节点,插入到每个使用过该内存块的stream中,且位于该块最后一次被使用的操作之后,用于标记 “内存块已空闲”。
- Terminal Node:流或捕获图中 “最新操作” 的集合,新捕获的操作会附加在终端节点之后。对于正在捕获的流,可通过cudaStreamGetCaptureInfo的dependencies_out参数获取终端节点集合。
内存块可重用性判断规则
cudaGraph生成一个DAG,因此作者提出了两种平衡 “安全性” 与 “灵活性” 的判断规则:
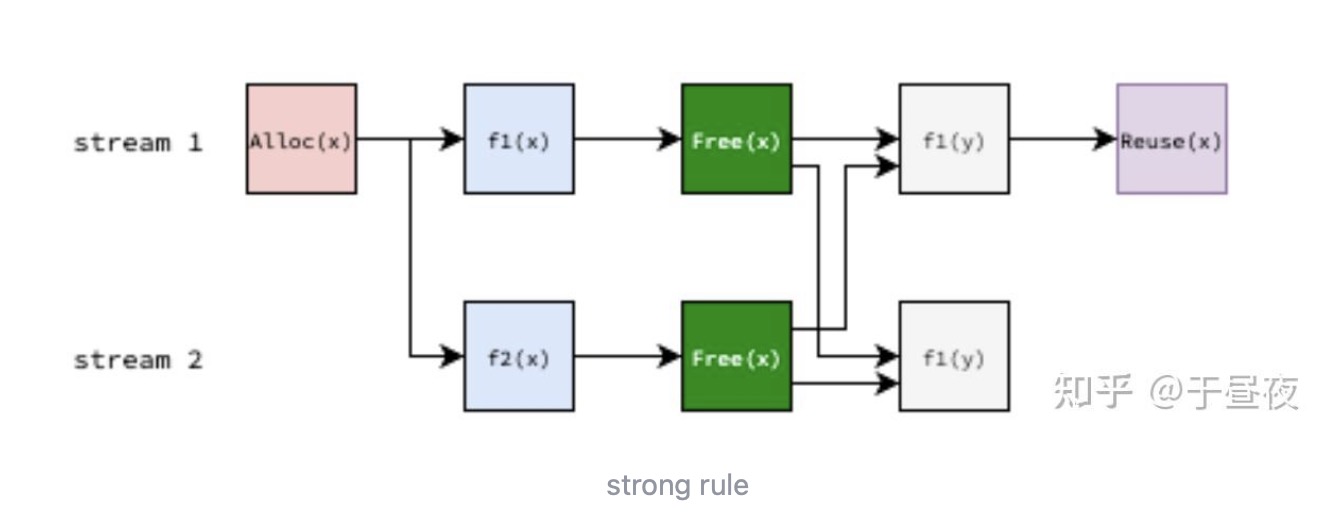
- Strong Rule (Graph-Wide Safety):从全局保障安全,规定若内存块的所有空闲标记均为所有活跃流的终端节点的 “前驱节点”,则该块可安全重用,通过严格的全局执行顺序避免重放时的生命周期重叠;
- Per-stream Rule (A Practical Optimization): 仅验证单流,对于流 S 上的分配请求,若内存块的所有空闲标记是流 S 的终端节点的前驱节点,即可在流 S 上重用,因此无需验证全图安全性。
核心实现流程
捕获期间执行free
- 对block->stream_uses中的每个流及 “分配流”,插入free marker,关联对应的block和free marker所对应的空node
if (CUDAAllocatorConfig::graph_capture_record_stream_reuse()) {
deferred_blocks.emplace(block, insert_free_marker(block)); // 插入free marker
} else {
deferred_blocks.emplace(block, std::vector<cudaGraphNode_t>{}); // 捕获结束后访问
}
- 捕获期间malloc
if (CUDAAllocatorConfig::graph_capture_record_stream_reuse()) {
free_safe_blocks_in_capture(context, stream);
}
free_safe_blocks_in_capture函数内容:
get_reusable_empty_nodes通过获取当前流的终端节点,通过反向 DFS 遍历每个终端节点的依赖链,统计空闲节点能到达的终端数量;最终筛选出 “能到达所有终端节点” 的空闲节点,构成当前流可复用的空闲节点集合,从而判断哪些free marker属于当前流可复用空闲节点,之后,判断free时载入过的block中哪些可以被正确复用,如果可复用则释放:
auto reusable_empty_nodes = get_reusable_empty_nodes(stream);
if (reusable_empty_nodes.empty()) {
return;
}
std::vector<Block*> blocks_to_erase; // 记录待删除的块
for (auto& [block, inserted_empty_nodes] : deferred_blocks) {
// 跳过两类块:1. 无空闲标记的块(无法判断安全);2. 分配流≠当前流的块
if (inserted_empty_nodes.empty() || block->stream != stream) {
continue;
}
// 该块的所有空闲标记是否都在reusable_empty_nodes中
bool is_reusable = true;
for (const auto& node : inserted_empty_nodes) {
if (reusable_empty_nodes.find(node) == reusable_empty_nodes.end()) {
is_reusable = false;
break;
}
}
// 若所有标记都安全 → 该块可回收
if (is_reusable) {
// 清除stream_uses:Graph已通过依赖保证同步,无需再跟踪多流使用
block->stream_uses.clear();
// 将块回收到空闲列表
free_block(block, context);
// 记录该块,后续从deferred_blocks中删除
blocks_to_erase.push_back(block);
}
}
现在,只要开启graph_capture_record_stream_reuse,pytorch会自动尝试在cuda_graph中通过插入free marker来提前释放一些block,使其生命周期变短,而不再是等到捕获完全结束时一次性释放。